
Why Intelligence Exists - and What That Means for AI
A first-principles exploration of why intelligence emerged, how prediction and resource allocation shape adaptive behavior, and what this implies for the future of artificial intelligence.
Intelligence exists because organisms must act under uncertainty while the world continues to change. A system that survives must continually form expectations about what will happen next, choose actions that influence those outcomes, and update its internal understanding when those expectations fail. Intelligence is not merely the capacity to represent patterns in data. It is a process embedded in time: prediction under consequence.
Modern deep learning systems, including large language models, have demonstrated an extraordinary capacity to represent structure in large datasets. Yet representation alone does not fully address the conditions under which intelligence originally evolved. The natural world does not present static datasets. It presents ongoing streams of signals in which actions alter future observations and errors carry consequences.
The central thesis of this essay is therefore modest but important: more general forms of artificial intelligence will likely require architectural properties that couple learning directly to ongoing interaction with changing environments, because intelligence evolved as a continuous process rather than a sequence of training episodes.
This argument does not diminish the achievements of deep learning. On the contrary, those achievements make the next question unavoidable. If deep learning excels at extracting structure from vast datasets, what architectural properties might be required once systems must operate persistently in environments that continue to change?
A useful first principle is simple: intelligence emerged because organisms must allocate limited resources while facing uncertain futures.
Every organism lives inside a stream of observations. Temperature changes, predators appear, food sources move, and energy reserves fluctuate. The organism must form expectations about what will happen next and choose actions that improve its chances of survival. Prediction is therefore inseparable from consequence. An incorrect expectation can waste energy, reduce reproductive success, or lead to death.
Two properties follow directly from this principle.
First, learning occurs while the organism continues to act. There is no pause in which the organism withdraws from the environment to retrain its internal models. Experience arrives continuously, and internal adjustments occur while the organism remains embedded in its surroundings.
Second, learning is coupled to outcomes. Expectations are revised not simply because patterns appear in sensory input, but because the organism observes the consequences of its own actions.
From this perspective, intelligence is less a static capability than a continuous loop: expectation, action, observation, revision.
Any argument about the future of artificial intelligence must begin by acknowledging what deep learning has achieved.
Large language models and related architectures have demonstrated a remarkable ability to extract structure from vast datasets. They can generate coherent text, translate between languages, summarize documents, write computer code, and assist with complex reasoning tasks. Vision models classify images and detect objects with accuracy that surpasses earlier approaches.
These systems succeed because deep neural networks are extremely effective representation learners. When trained on large corpora, they capture statistical regularities spanning enormous ranges of contexts. Transformers, in particular, model relationships across long sequences of tokens, enabling outputs that appear contextually appropriate in many situations.
This ability to learn high-dimensional representations has changed the landscape of artificial intelligence. Tasks that once required extensive hand-engineering can now be approached through large-scale training.
The achievements are genuine. They demonstrate that powerful general-purpose pattern extraction is possible.
Yet these successes also highlight a deeper question: representation alone does not guarantee adaptive behavior in environments that continue to change.
It would be misleading to suggest that modern systems cannot handle novelty. Large models routinely respond to situations that were never explicitly encountered during training by composing learned structures in new ways.
A language model reasoning about an unfamiliar problem does not simply retrieve a memorized answer. It combines patterns learned from many contexts—linguistic structures, fragments of world knowledge, reasoning templates, and procedural heuristics. The resulting behavior can appear surprisingly flexible.
This raises an important question. When a model solves a problem it has never seen before by recombining familiar operations, is that not already a form of discovery?
In practice, the boundary is not sharp. Rich representations allow systems to construct solutions that were never explicitly present in their training data. Modern AI already exhibits a meaningful capacity to navigate novelty.
But a distinction is needed. Composing known elements into a new solution is different from recognizing that the elements themselves—the assumptions, the relationships, the governing structure—have changed. A system may be brilliantly flexible within its learned framework without ever detecting that the framework no longer fits.
A conceptual distinction helps clarify the issue: representation versus coupling.
Representation refers to the internal structures a system learns about the world. In deep learning, these structures are encoded in model parameters and latent activations. Training adjusts those parameters so the model captures patterns present in its dataset.
Coupling, by contrast, refers to how a system remains connected to ongoing consequences in the environment while it operates. A coupled system continually compares expectations to outcomes and updates its internal state accordingly.
Most current AI systems emphasize representation. They undergo a training phase in which parameters are optimized, followed by an inference phase in which those parameters remain largely fixed. The system applies the knowledge embedded during training but does not fundamentally revise that knowledge during operation.
This separation has practical advantages. Training can be carefully controlled, and inference becomes computationally efficient.
However, the separation also introduces a structural limitation: the system's internal understanding does not change as it experiences the environment, except through later retraining cycles.
This architectural separation leads to several observable limitations when systems operate in dynamic environments.
First, models cannot easily incorporate new evidence while they run. When the underlying data distribution shifts, predictions may degrade until retraining occurs.
Second, knowledge discovered during deployment remains ephemeral. A model may successfully solve a novel problem through reasoning or pattern recombination, yet that discovery does not become part of the system's persistent repertoire. If the same problem appears again later, the model does not recall having solved it. It reconstructs a solution from scratch.
In biological systems, discovery often leaves a trace. Experiences modify internal state, forming memories that influence future behavior. A useful strategy learned once can become part of the organism's repertoire. Most deployed machine learning systems operate differently. Learning occurs during training; deployment is dominated by inference. The system may demonstrate novel reasoning, but it does not automatically incorporate the result into its own capabilities.
Third, models do not directly associate actions with consequences. They generate outputs conditioned on input patterns but do not maintain a continuously updated record of how those outputs affected subsequent events.
These limitations are not defects in the design of deep learning systems. They reflect the assumptions under which those systems were built: large datasets, offline training, and tasks that can be evaluated through static benchmarks.
The question is whether these assumptions remain adequate once AI systems must operate persistently in changing environments.
One architectural property appears largely absent from most current AI systems: continuous consequence coupling.
Operationally, continuous consequence coupling would mean that a system updates aspects of its internal state whenever new observations arrive that reveal the outcome of earlier predictions or actions.
Such a property would enable a system to refine its expectations as the environment evolves rather than waiting for periodic retraining.
The signals involved would include three elements: incoming observations from the environment, records of the system's previous predictions or actions, and outcome signals indicating whether those expectations were confirmed or violated.
At runtime, these signals would modify internal memory structures that store relationships between situations, predictions, and outcomes. The adjustment would occur continuously while the system remains active.
Consider a financial trading system built on deep learning. The model has learned rich representations of market dynamics from historical data. For months, it performs well—recognizing patterns, anticipating price movements, adjusting positions.
Then monetary policy shifts. The relationships between interest rates, asset prices, and volatility that held for years begin to change. The model's predictions degrade, not because it lacks analytical sophistication, but because the governing structure of the environment has shifted.
A system with continuous consequence coupling would begin registering discrepancies between its predictions and observed outcomes as they accumulated. Rather than waiting for a scheduled retraining cycle, it could start adjusting its expectations—cautiously, within bounded limits—while continuing to operate.
A system without this property continues applying outdated assumptions until an external process intervenes.
The distinction is architectural rather than algorithmic. Many different learning rules could implement consequence coupling. What matters is that the system remains structurally connected to the consequences of its own expectations.
Continuous consequence coupling introduces a problem that static systems avoid entirely: the system must decide not only what to predict, but when to revise itself and when to hold steady.
This is where the distinction between aleatoric and epistemic uncertainty becomes practically important.
Some discrepancies between prediction and outcome reflect irreducible variability—noise in the environment, stochastic events, measurement limitations. A system that treats every surprise as a reason to revise will constantly rewrite itself in response to fluctuations, gradually eroding previously useful structure.
Other discrepancies reflect genuine structural change—a new regime, a shifted relationship, a degraded assumption. A system that treats every surprise as noise will carry forward outdated models long after the environment has moved on.
A self-updating system must therefore maintain a principled distinction between these cases. It needs mechanisms that allow it to withhold commitment under irreducible noise while revising its structure when accumulated evidence points to genuine change.
This is not a parameter to tune once. It recurs at runtime as an ongoing judgment about what kind of uncertainty the system faces. Architecturally, it requires that the pathway from consequence to revision be both bounded (so that noise does not cascade into structural damage) and inspectable (so that when the system does change, the change can be traced to evidence and examined).
Three claims follow from the preceding argument.
Claim 1: More general intelligence will likely require systems that learn during operation, because environments change while decisions are being made.
If this claim is wrong, then static models with periodic retraining should remain competitive in domains where conditions evolve continuously.
Claim 2: Representation learning alone is insufficient for adaptive intelligence, because intelligence depends on how expectations interact with consequences over time.
This claim would weaken if static models consistently matched or surpassed adaptive systems in environments with rapid structural change.
Claim 3: Architectural coupling to outcome signals will become increasingly important as AI systems move from static datasets into live environments.
This claim could be falsified if systems that remain decoupled from consequences nevertheless demonstrate stable performance in highly dynamic domains.
These claims do not imply that deep learning is obsolete. Representation learning will likely remain a foundational component of intelligent systems. Rich anticipatory structure may in fact be a prerequisite for effective discovery—the more deeply a system understands its environment, the more clearly it can detect when that understanding has broken down.
The question is whether additional architectural properties must be layered on top.
One reason this problem persists is that continuous adaptation introduces practical challenges that static architectures avoid.
Updating a system while it operates raises risks of instability. Incorrect updates could accumulate and degrade performance. The system itself becomes part of what is drifting—even if each individual update is small, their accumulation can relocate the system to a qualitatively different behavioral regime.
Furthermore, the signals required for consequence coupling are not always readily available. Many environments do not provide immediate or unambiguous feedback about whether a decision was correct.
There is also a difficulty that biological analogies tend to obscure. Organisms learn continuously, but they operate under massive evolutionary selection pressure that prunes organisms whose continuous learning goes wrong. Nature has an external filter for failed adaptation. Engineered systems do not have this filter by default—they need it built in, through bounded revision, monitoring, rollback mechanisms, and careful governance of the update pathway.
These difficulties help explain why the dominant paradigm has emphasized large-scale offline training. It provides control and stability.
Yet biological systems demonstrate that continuous learning under consequence is possible. The challenge is replicating not just the adaptivity but also the constraints that keep it from becoming a source of instability.
The search for more general intelligence may therefore hinge less on discovering new algorithms than on reconsidering the architecture of learning systems.
Instead of asking how to train larger models on larger datasets, a different question emerges: how should artificial systems remain connected to the consequences of their own predictions over time—and how should the resulting changes be governed?
Deep learning has shown that machines can acquire rich internal representations. The next challenge may involve embedding those representations within systems that continue to revise themselves as they interact with the world, while maintaining the stability and inspectability required for that revision to be trustworthy.
Whether such architectures will prove practical remains uncertain. Continuous learning introduces risks, and many engineering problems remain unresolved.
Yet the question itself reflects the conditions under which intelligence originally evolved. Intelligence did not emerge in static datasets. It emerged in organisms that had to act, observe outcomes, and adjust while time continued to pass.
Understanding how to replicate that property—and how to govern it—may prove as important as the advances that made modern AI possible.
Continuous consequence coupling is an architectural property in which a system continuously updates internal memory or parameters based on the outcomes of its previous predictions or actions. The system records expectations, observes subsequent results, and adjusts its internal structures while it operates.
Representation learning refers to the process by which a model discovers internal structures that capture patterns in data. In deep learning, these structures are encoded in model parameters and latent activations learned during training.
Not exactly. Reinforcement learning focuses on optimizing actions to maximize cumulative reward. Continuous consequence coupling is a broader architectural concept. It describes how systems remain connected to outcome signals during operation, regardless of whether those signals are framed as rewards. The governance problem—deciding when to revise versus when to hold steady—extends beyond reward maximization.
Yes. Many research efforts address continual learning, online learning, and adaptive systems. The argument here is not that such ideas are absent, but that most large-scale deployed AI systems still rely primarily on the training–inference separation, and that bridging this gap requires treating the update pathway as a first-class architectural concern rather than a feature added to an existing design.
One practical test would involve deploying two forecasting systems in an environment with known regime changes. One system would remain static between retraining cycles. The other would incorporate continuous consequence coupling, updating its expectations as discrepancies accumulate. Comparing performance before and after structural changes would reveal whether the adaptive architecture provides measurable advantages. The test should also measure stability: whether the adaptive system maintains performance during periods when the environment is not changing, or whether continuous updating introduces unnecessary drift.
A first-principles exploration of why intelligence emerged, how prediction and resource allocation shape adaptive behavior, and what this implies for the future of artificial intelligence.

Strong generalization can still fall short of true intelligence. We examine the critical difference between representational breadth and adaptive coupling to consequence over time.
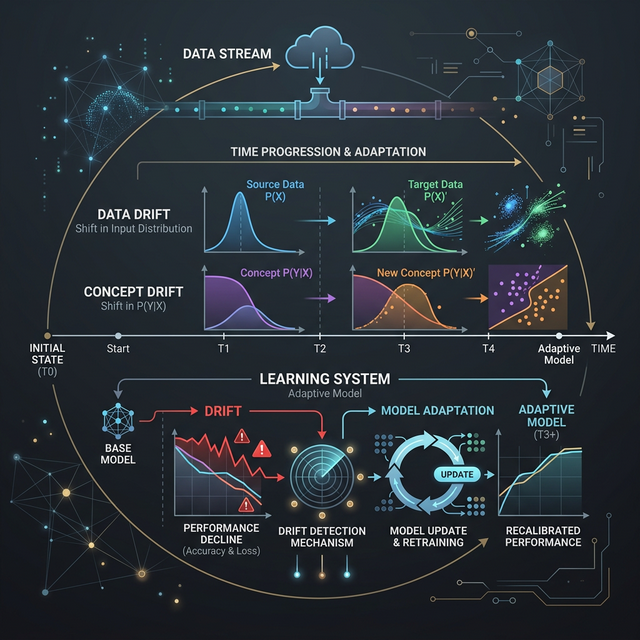
Learning systems face challenges when the statistical patterns of the world evolve faster than the model can adapt. We explore data, label, and concept drift.
We are currently engaging with investors and strategic partners interested in long-term technological impact grounded in scientific discipline.
Elysium Intellect represents a fundamentally different approach to artificial intelligence, prioritising continuous adaptation, reduced compute dependence, and real industrial application.
Conversations focus on collaboration, evidence building, and shared ambition.
Start a conversation